Designing DB schema for efficient pagination
Pagination queries doesn’t seem to be complex and doesn’t need optimisation until records in your table reaches a good number. Depending upon how frequently records in your table gets updated and how frequently they need to be accessed, you can add a layer of cache to avoid DB hits.
In this article though, we’ll focus on optimisations that can be done on DB side, specifically at design phase, so that your schema is future proof.
Suppose, you have to return 100 results per page and your DB has 1000000+ records. One way to do it could be, by use of OFFSET and LIMIT. See this query:
SELECT * FROM <table> OFFSET 100000 LIMIT 100;
For this query DB will first check 100100 rows then ignore first 100000 and return last 100 rows. This is waste of CPU operations and DB resources, you only needed 100 records right after 100000th records. Wouldn’t it be great if we can just do that only ?
The answer is yes, it’s possible. We can find records on the basis of Key range and then use LIMIT. Look at this query:
SELECT * FROM <table> where key > 100000 LIMIT 100;
For this query DB will find the record having key value 100000 and then return 100 results after it. Which will be much faster than previous query.
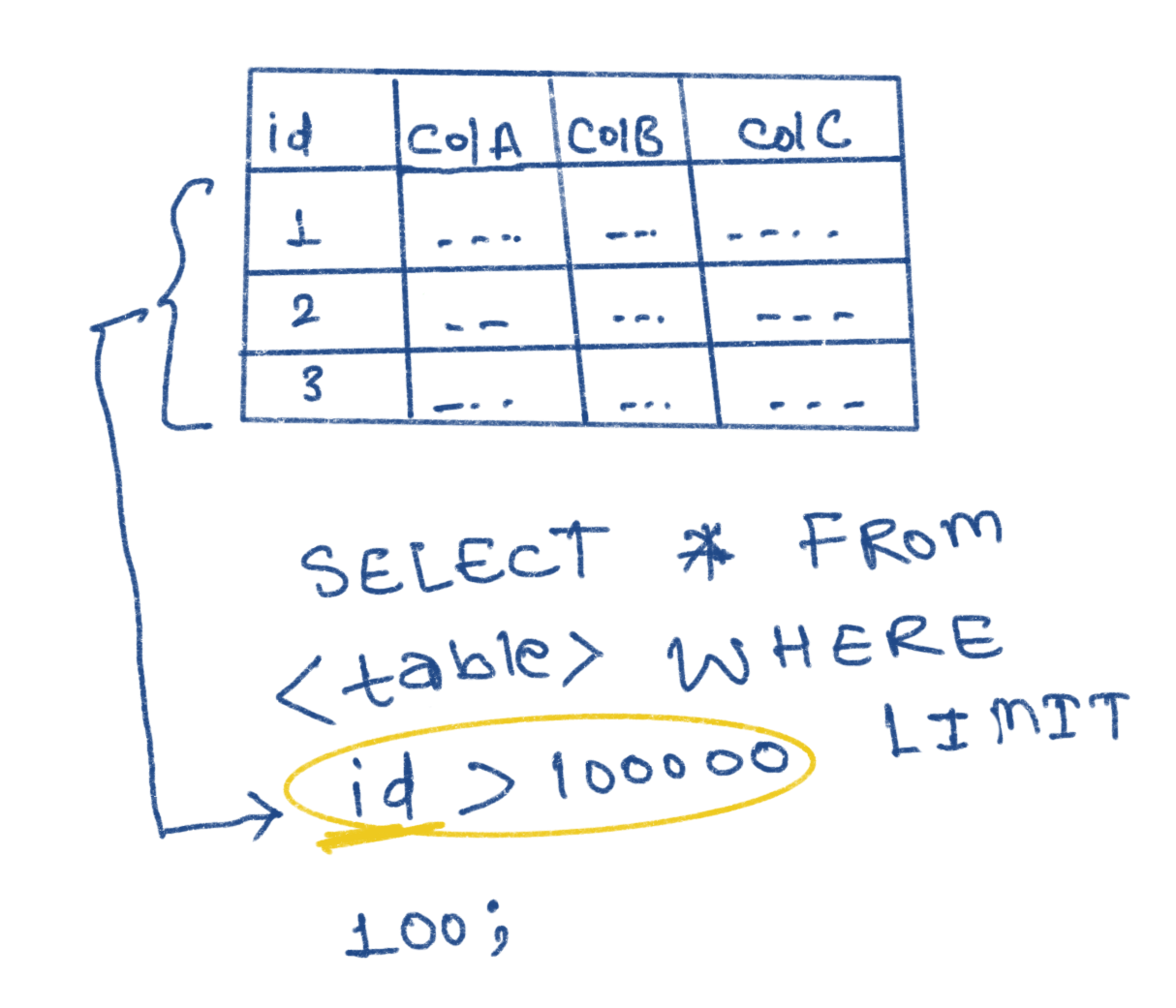
But there’s a catch, in order to make it work like this, we need to have key column present in the DB and that should be in sorted order. With this query, the CPU operations required to find 100000th record will be logarithmic, because the records are sorted hence DB will use binary search. Then, reading 100 rows post that will result in 100 more operations, which is okay.
So, here’s what you can do, while designing the schema of DB for faster pagination queries:
- Create indexes on the columns which you need to use as criteria often, to find results
- Have a column in sorted order (this can be ‘id’ column) and perform pagination on it.
- Use Key ranges instead of OFFSET.